


1) Node.js Under The Hood #1 - Getting to know our tools2) Node.js Under The Hood #2 - Understanding JavaScript
In our past article we discussed a few things about C++, what is Node.js, what is JavaScript, their stories, how they came to be and how they're now. We also talked a little about how a filesystem function is actually implemented in Node.js and how Node.js is actually divided into components.
Now, let's go to our second article of this series, in this article we're going to explore some aspects of JavaScript.
Let's put things in order. So, we got a glimpse of the appearance of the actual C++ code that runs underneath all the gibberish we write in Node.js, since JavaScript is the highest level component of Node.js, let's start by asking how our code runs, how do JavaScript even work?
Most of people actually knows a few said words and keep repeating them:
But have they dug deeper into these questions?
If you're able to answer more than 2 of those, consider yourself above average, because most JavaScript developers in general don't even know there's something at all behind this language... But, fear not, we're here to help, so let's dig deeper into the concept of JavaScript and how it really works and, most important, why other people bully it.
Nowadays, the most popular JavaScript engine is V8 (one of the best pieces softwares ever written by mankind, after Git). This is due to the simple fact that the most used browser is Chrome, or is based on Chromium - which is the open source browsing engine of Chrome - like Opera, Brave and so on... However it is not the only one. We have Chakra, written by Microsoft for the Edge browser, we have SpiderMonkey, written by Netscape – which now powers Firefox – and much others like Rhino, KJS, Nashorn and etc.
However, since V8 is used both on Chrome and Node.js, we're sticking with it. This is a very simplified view of what it looks like:

This engine consists, mainly, in two components:
We'll have a solo article for V8 later on
Most APIs developers use are provided by the engine itself, like we were able to see in the previous chapters when we wrote the readFile code. However, some APIs we use are not provided by the engine, like setTimeout, any sort of DOM manipulation, like document or even AJAX (the XMLHttpRequest object). Where are those comming from? Let's take our previous image and bring it into the harsh reality we live in:

The engine is just a tiny bit of what makes JavaScript, well... JavaScript... There are browser-provided APIs which we call Web APIs — or also, external APIs — these APIs (like DOM, AJAX and setTimeout) are provided by the browser vendors — in this case, for Chrome, it's Google — or by the runtime itself, like Node (with different APIs). And they are the main reason why most people hated (and still hate) JavaScript. When we look at today's JavaScript we see a field filled with packages and other stuff, but mostly homogeneous on every side. Well... It wasn't always like that.
Back in the day, before ES6 and waaay before Node.js even existed as an idea, there were no consensus on how to implement these APIs on the browser side, so every vendor had their own implementation of 'em, or not... Which meant that we had to be constantly checking and writing pieces of code that were meant to only work on specific browsers (do you remember IE?), so a particular browser could implement the XMLHttpRequest a bit different from other browsers, or the setTimeout function could be named sleep in some implementation; in the worst case scenario, the API would not even exist at all. This has been changing gradually, so now, thankfully, we have some consensus and some agreement on which APIs should exist and how they should be implemented, at least the most used and basic ones.
Aside of that, we have the infamous event loop and the callback queue. Which we'll be talking about later.
Most people have heard that JS is a single-threaded language, and they just accepted it as the final truth in the universe without ever really knowing why. Being single-threaded means we only have a single call stack, in other words, we can only execute one thing at a time.

The call stack is not a part of Javascript itself, it's a part of its engine, in our case, V8. But I'll put it here so we can have a sense of how things are suposed to work in a flow
Stacks are a abstract data type that serves as a collection of elements. The name "stack" comes from the analogy to a set of boxes stacked on top of each other, while it is easy to take a box off the top of the stack, taking a deeper box may require us to take several other items first.
The stack has two principal methods:
One thing to note about stacks is that the order of how the elements are pushed and popped really matters. In stacks, the order in which elements come off a stack is called LIFO, an acronym for Last In First Out, which is pretty self explanatory.
Additionally, we can have another method called
peek, which reads the most recently added item (the top of the stack) without removing it.
All we need to know about stacks are these topics:
Basically, in JS, the stack records the position we are currently executing in our program. If we step into a function, calling it, we put that call on the top of the stack. After we return from a function, we pop the top of the stack. Each of these calls is called a Stack Frame.
Let's take as first example, a simple program, different from the one we had:
function multiply (x, y) {
return x * y
}
function printSquare (x) {
const s = multiply(x, x)
console.log(s)
}
printSquare(5)
We'll run our
readFilecode later on when we have glued all the pieces together
When the engine runs the code, at first, the call stack will be empty. After each step, it'll be filling up with the following:
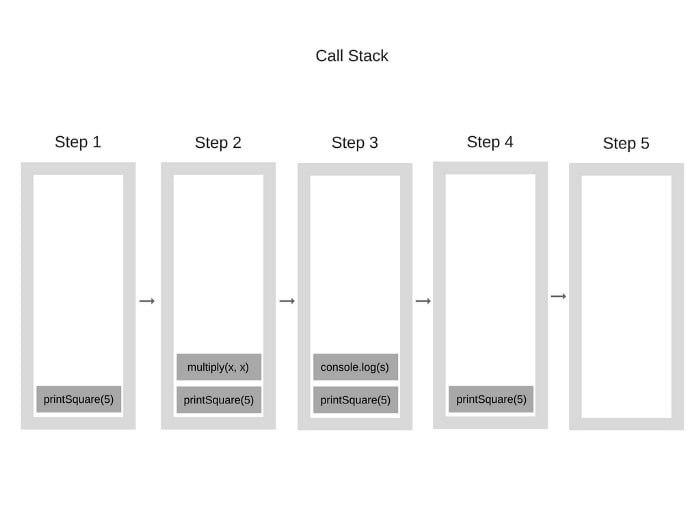
Let's go in bit by bit:
printSquare(5), since all other lines are just declarations.printSquare function definition
const s = multiply(x, x), so let's add the multiply(x, x) to the top of the stackmultiply, no function calls, nothing is added to the stack. We only evaluate x * y and return it.multiply(x, x). So now let's go on to the line just after the last line we evaluated, it's the console.log line.
console.log is a function call, let's add to the top of the stackconsole.log(s) runs, we can pop it off the stackprintSquare(5), which was the first we added
Stacks are exactly how stack traces are constructed when an exception is thrown. A stack trace is basically the printed out state of the call stack when the exception happened:
function foo () {
throw new Error('Exception');
}
function bar () {
foo()
}
function start () {
bar()
}
start()
This should print something like:
Uncaught Error: Exception foo.js:2
at foo (foo.js:2)
at bat (foo.js:6)
at start (foo.js:10)
at foo.js:13
The at phrases are just our call stack state.
No, the stack is not named after the site, sorry to disappoint. Actually, the site is named after one of the most common errors found in programming since the beginning of computation: the stack overflow.
A stack overflow error happens when we reach the maximum call stack size. Stacks are data structures, which means they're allocated in memory, and memory is not infinite, so this can happen rather easily, specially on non-sanitized recursive functions, like this:
function f () {
return f()
}
f()
At every call of f we'll pile up f in the stack, but, as we saw, we can never remove an item from the stack before it has reached the end of its execution, in other words, when the code reaches a point where no functions are called. So our stack would be blown because we have no termination condition:

Thankfully, the engine is watching us and realizes the function would never stop calling itself, causing an stack overflow, which is a pretty serious error, since it crashes the whole application. If not stopped, can crash or damage the stack memory for the whole runtime.
Running in a single-thread environment can be very liberating, since it's much simpler than running in a multi-threaded world where we'd have to care about racing conditions and deadlocks. In this world, such things do not exist, after all, we are only doing one thing at once.
However, single-threading can also be very limiting. Since we have a single stack, what would happen if this stacked is blocked by some slow-running code?
This is what we're going to find out in the next article...


![]()
![]()
We are a leading niche digital & tech recruitment specialist for the North East of England. We Specialise in the acquisition of high-performing technology talent across a variety of IT sectors including Digital & Technology Software Development.
Our ultimate goal is to make a positive impact on every client and candidate we serve - from the initial call and introduction, right up to the final delivery, we want our clients and candidates to feel they have had a beneficial and productive experience.
If you’re looking to start your journey in sourcing talent or find your dream job, you’ll need a passionate, motivated team of experts to guide you. Check out our Jobs page for open vacancies. If interested, contact us or call 0191 620 0123 for a quick chat with our team.
Follow us on our blog, Facebook, LinkedIn, Twitter or Instagram to follow industry news, events, success stories and new blogs releases.
Back to Blog
Northumbria House, Samson Close, Killingworth, Newcastle, NE12 6DX

