

In this tutorial you will learn how to use ML to predict wine price, points and variety from the text description.
We will process the wine description text with the library SciKit Learn to create a Bag-of-Words Logistic Regression Multi-Classification model. If that didn't make sense then you are in the right place! If it did make sense continue reading because wine.
There are two options: cloud or local.
Azure Cloud Setup - Use Azure Machine Learning Workspace with the integrated cloud Notebook VMs. Workspace gives you a LOT of functionality and I would highly recommend this.
Create a free Azure account if you dont already have one.
Follow the Create Workspace tutorial through the "Create a notebook VM" step
Click "Jupyter Lab" from the Notebook VM navigation
Then run the below command in the terminal to clone the notebook from GitHub.

#CTRL+SHIFT+V to paste
curl https://raw.githubusercontent.com/cassieview/intro-nlp-wine-reviews/master/winereview-nlp.ipynb --output winereview-nlp.ipynb
Once you are set with one of the above environment configurations its time to start building!
If you get an error "No module named" install it with the command !pip install wordcloud. Replace wordcloud with the module name in the error message.
#This package need to be installed first
!pip install wordcloud
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_curve
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
from joblib import dump, load
We need data! I used a dataset I found on Kaggle. Kaggle is an online community of data scientists. Download the dataset from the github repo or kaggle.
Import the data as a Pandas DataFrame
#File path to the csv file
csv_file = "https://raw.githubusercontent.com/cassieview/intro-nlp-wine-reviews/master/dataset/winemag-review.csv"
# Read csv file into dataframe
df = pd.read_csv(csv_file)
# Print first 5 rows in the dataframe
df.head()

Once we have the data then its time to analyze it and do some Feature Selection and Engineering. We will visualize our data using Seaborn. This will allow us to see if there is a strong correlation between different data points and help us answer questions about our data. Since our initial question was around predicting price, points or variety from the description we already know that our Feature will be the descriptionand our Label will be price, pointsor variety. Features are the data we use to make predictions and Labels are what we are predicting. Each label will be a separate model so there will be three models in total if you choose to build all three predictive models.
For fun, let's ask some questions about the data and answer them by graphing it with Seaborn.
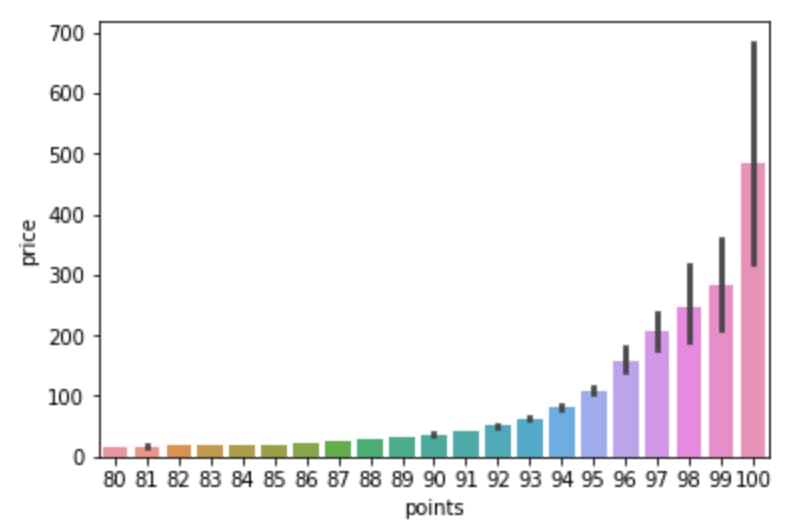
Is there a correlation between price and points?
sns.barplot(x = 'points', y = 'price', data = df)
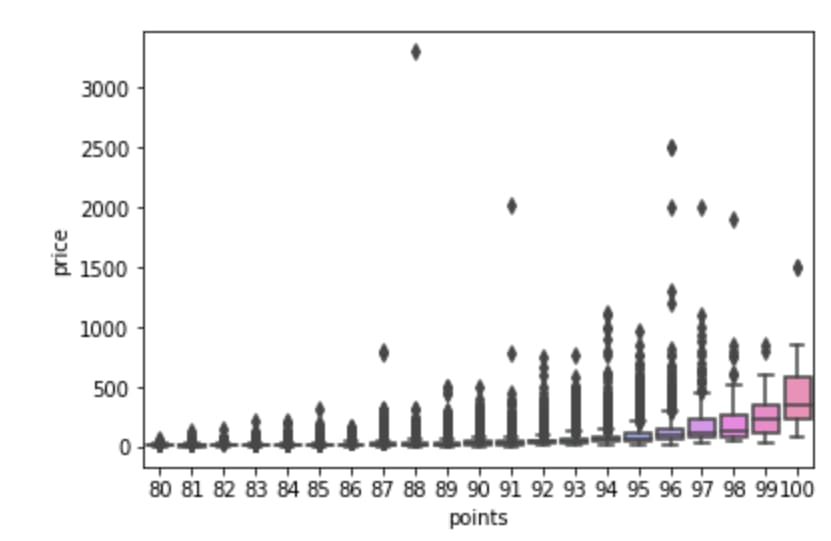
sns.boxplot(x = 'points', y = 'price', data = df)
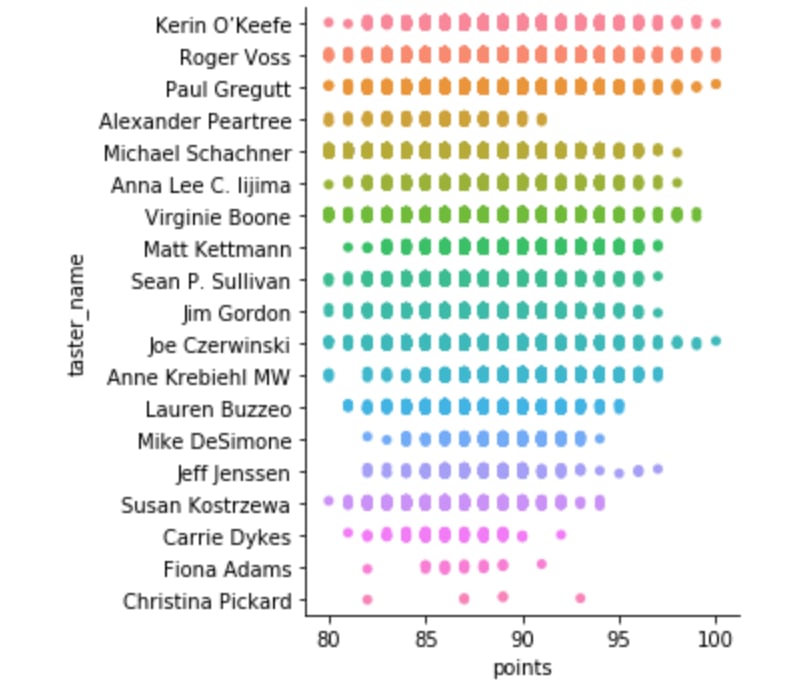
Does one wine critic give higher ratings than the others?
sns.catplot(x = 'points', y = 'taster_name', data = df)
Let's look at a WordCloud of the description Text
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
text = df.description.values
wordcloud = WordCloud(
width = 3000,
height = 2000,
background_color = 'black',
stopwords = STOPWORDS).generate(str(text))
fig = plt.figure(
figsize = (40, 30),
facecolor = 'k',
edgecolor = 'k')
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
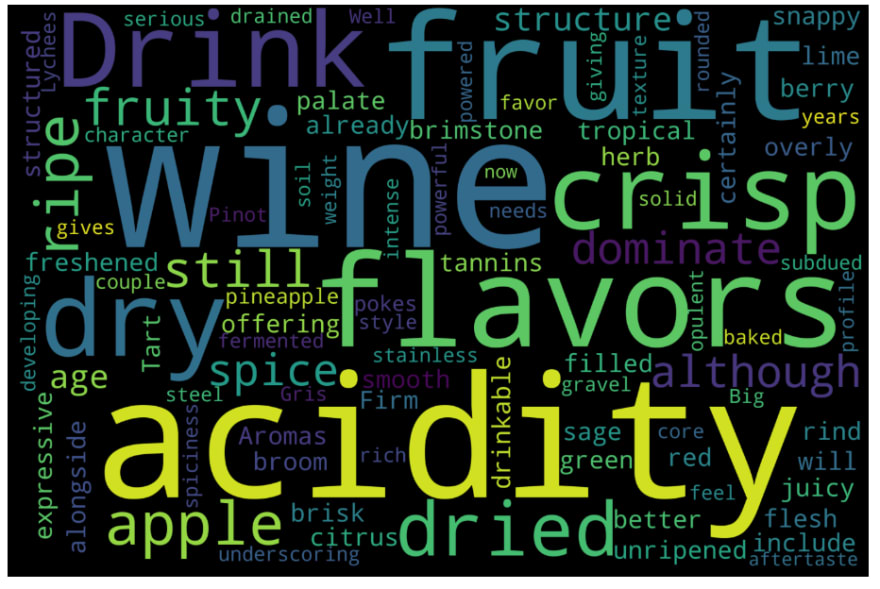
I like to think of this WordCloud as a cheatsheet of discriptive words to use when tasting wine to make yourself sound like a wine expert ????
What other questions could you ask and answer by graphing this data?
This is going to be multi-classification for the price points or grape variety of the wines reviewed by the wine critics. Right now our points and price are number features. This needs to be updated to a text feature category, to do this we will create a couple functions to generate calculated columns based on the values in the points and price columns to use as are our labels.
Create quality column from points values to classes of bad, ok, good, and great. Below is a function to return string quality based on the points value.
def getQuality(points):
if(points <= 85):
return 'bad'
elif(points<=90 ):
return 'ok'
elif(points<=95):
return 'good'
elif(points<=100):
return 'great'
else:
return 'If this gets hit, we did something wrong!'
Next apply the function to the points column of the dataframe and add a new column named quality.
df['quality'] = df['points'].apply(getQuality)
Visualize the new column against the price column like we did above.
sns.catplot(x = 'quality', y = 'price', data = df)

sns.barplot(x = 'quality', y = 'price', data = df)
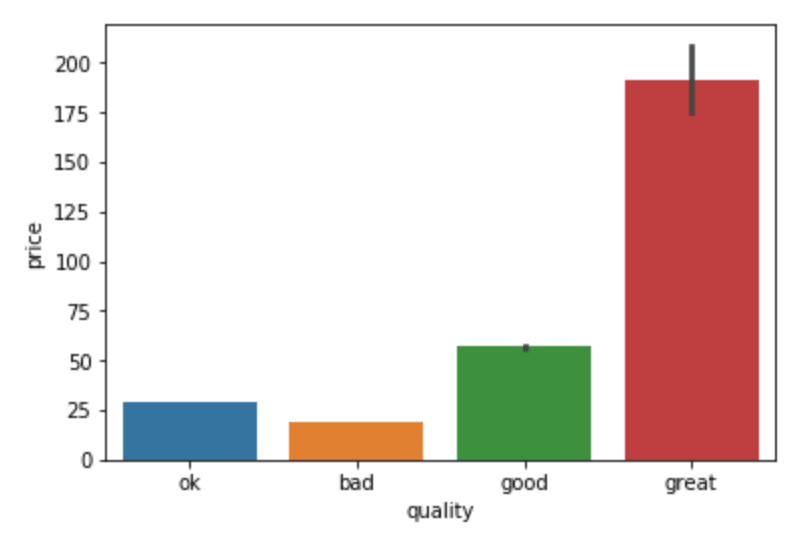
Create priceRange column from price column of 1-30, 31-50, 51-100, Above 100 and 0 for columns with NaN. Below is a function to return string priceRange based on price value.
def getPriceRange(price):
if(price <= 30):
return '1-30'
elif(price<=50):
return '31-50'
elif(price<=100):
return '51-100'
elif(math.isnan(price)):
return '0'
else:
return 'Above 100'
Apply the function to the points column of the dataframe and add a new column named priceRange.
df['priceRange'] = df['price'].apply(getPriceRange)
Print totals for each priceRange assigned to see how the labels are distributed
df.groupby(df['priceRange']).size()
Output: priceRange
0 8996
1-30 73455
31-50 27746
51-100 16408
Above 100 3366
dtype: int64
We now have our labels for models to predict quality, priceRange and grape variety.
The docs do a great job of explaining the CountVectorizer. I recommend reading through them to get a full understanding of whats going on, however I will go over some of the basics here.
At a high level the CountVectorizer is taking the text of the description, removing stop words (such as “the”, “a”, “an”, “in”), creating a tokenization of the words and then creating a vector of numbers that represents the description. The text description is now represented as numbers with only the words we care about and can be processed by the computer to train a model. Remember the computer understand numbers and words can be represented as numbers so the computer can "understand".
This is an example of how the words become numbers. We will go over this in more detail with an example from the dataset as well.

Before we jump into the CountVectorizer code and functionality. I want to list out some terms and point out that CountVectorizer does not do the Lemmatization or Stemming for you.
N-Gram: A feature extraction scheme for text data: any sequence of N words turns into a feature value.
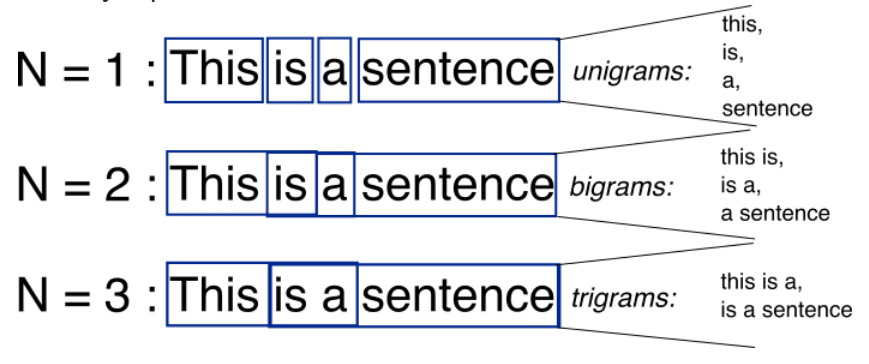
Lemmatization: converts multiple related words to a single canonical form ("fruity", "fruitiness" and "fruits" would all become "fruit")
Stemming: Similar to Lemmatization but a bit more aggressive and can leave words fragmented.
These are all the properties that you can set within the CountVectorizer. Many of them are defaulted or if set override other parts of the CountVectorizer. We are going to leave most of the defaults and then play with changing some of them to get better results for our model.
CountVectorizer(
input='content', encoding='utf-8', decode_error='strict',
strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None,
stop_words=None, token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1),
analyzer='word', max_df=1.0, min_df=1, max_features=None,
vocabulary=None, binary=False, dtype=
)
Create the function to get the vector and vectorizer from the descriptionfeature.
There are different CountVectorizer configurations commented out so that we can play with different configs and see how it changes our result. Additionally this will help us look at one description and pick apart what is actually happening in the CountVectorizer.
def get_vector_feature_matrix(description):
vectorizer = CountVectorizer(lowercase=True, stop_words="english", max_features=5)
#vectorizer = CountVectorizer(lowercase=True, stop_words="english")
#vectorizer = CountVectorizer(lowercase=True, stop_words="english",ngram_range=(1, 2), max_features=20)
#vectorizer = CountVectorizer(lowercase=True, stop_words="english", tokenizer=stemming_tokenizer)
vector = vectorizer.fit_transform(np.array(description))
return vector, vectorizer
For the first run we are going to have the below config. What this is saying is that we want to convert the text to lowercase, remove the english stopwords and we only want 5 words as feature tokens.
vectorizer = CountVectorizer(lowercase=True, stop_words="english", max_features=5)
#Optional: remove any rows with NaN values.
#df = df.dropna()
Next let's call our function and pass in the description column from the dataframe.
This returns the vector and the vectorizer. The vectorizer is what we apply to our text to create the number vector representation of our text so that the machine learning model can learn.
vector, vectorizer = get_vector_feature_matrix(df['description'])
If we print the vectorizer we can see the current default parameters for it.
print(vectorizer)
Output: CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=5, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words='english',
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
Examine our variables and data to understand whats happening here.
print(vectorizer.get_feature_names())
Output: ['aromas', 'flavors', 'fruit', 'palate', 'wine']
Here we are getting the features of the vectorizer. Because we told the CountVectorizer to have a max_feature = 5 it will build a vocabulary that only considers the top feature words ordered by term frequency across the corpus. This means that our description vectors would only include these words when they are tokenized, all the other words would be ignored.
Print out our first description and first vector to see this represented.
print(vector.toarray()[0])
Output: [1 0 1 1 0]
df['description'].iloc[0]
Output: "_Aromas_ include tropical _fruit_, broom, brimstone and dried herb. The _palate_ isn't overly expressive, offering unripened apple, citrus and dried sage alongside brisk acidity."
The vector array ([1 0 1 1 0]) that represents the vectorization features (['aromas', 'flavors', 'fruit', 'palate', 'wine']) in first description in the corpus. 1 indicates its present and 0 indicates not present in the order of the vectorization features.
Play around with different indexes of the vector and description. You will notice that there isn't lemmatization so words like fruity and fruits are being ignored since only fruit is included in the vector and we didn't lemmatize the description to transform them into their root word.
Update the function so that the second vectorizer configuration is being used.
def get_vector_feature_matrix(description):
#vectorizer = CountVectorizer(lowercase=True, stop_words="english", max_features=5)
vectorizer = CountVectorizer(lowercase=True, stop_words="english", max_features=1000)
#vectorizer = CountVectorizer(lowercase=True, stop_words="english",ngram_range=(1, 2), max_features=1000)
#vectorizer = CountVectorizer(lowercase=True, stop_words="english", tokenizer=stemming_tokenizer)
vector = vectorizer.fit_transform(np.array(description))
return vector, vectorizer
And call the function to update the vectorizer
vector, vectorizer = get_vector_feature_matrix(df['description'])
Now create our feature matrix. If you get a MemoryError here reduce the max_features in the CountVectorizer.
features = vector.todense()
We have three different labels for three different models. Let's assign the label variable next and use the quality label first.
label = df['quality']
#label = df['priceRange']
#label = df['variety']
We have the features and label variables created. Next we need to split the data to train and test.
We are going to use 80% to train and 20% to test. This will allow us to get an accuracy estimation from the training to see how the model is performing.
X, y = features, label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Train the model using a LogisticRegression algorithm and print the accuracy.
lr = LogisticRegression(multi_class='ovr',solver='lbfgs')
model = lr.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print ("Accuracy is {}".format(accuracy))
Output: "Accuracy is 0.7404885554914407"
This is an ok accuracy but I am sure it can be improved! For this tutorial we are going to call it "good enough" which is a decision that needs to be made with every model you ever build!
When you select a candidate model it should always be tested on unseen data. If a model is overfitted to its data it will perform really will on its own data and poorly on new data. This is why its very important to test on unseen data.
I grabbed this review from the wine mag site. Its a 95 point and $60 bottle of wine review.
test = "This comes from the producer's coolest estate near the town of Freestone. White pepper jumps from the glass alongside accents of lavender, rose and spice. Compelling in every way, it offers juicy raspberry fruit that's focused, pure and undeniably delicious."
x = vectorizer.transform(np.array([test]))
proba = model.predict_proba(x)
classes = model.classes_
resultdf = pd.DataFrame(data=proba, columns=classes)
resultdf

Another way to look at the result is to transpose, sort and then print the head resulting in a list of the top 5 predictions.
topPrediction = resultdf.T.sort_values(by=[0], ascending = [False])
topPrediction.head()
Data science is a trial and error process. I am sure there are ways to improve this model and accuracy. Play around and see if you can get a better result!
The Machine Learning Algorithm Cheat Sheet
How to choose algorithms for Azure Machine Learning Studio
CHEERS!

Drinking wine and hanging out with bots.

![]() https://twitter.com/Cassieview
https://twitter.com/Cassieview
We are a leading niche digital & tech recruitment specialist for the North East of England. We Specialise in the acquisition of high-performing technology talent across a variety of IT sectors including Digital & Technology Software Development.
Our ultimate goal is to make a positive impact on every client and candidate we serve - from the initial call and introduction, right up to the final delivery, we want our clients and candidates to feel they have had a beneficial and productive experience.
If you’re looking to start your journey in sourcing talent or find your dream job, you’ll need a passionate, motivated team of experts to guide you. Check out our Jobs page for open vacancies. If interested, contact us or call 0191 620 0123 for a quick chat with our team.
Follow us on our blog, Facebook, LinkedIn, Twitter or Instagram to follow industry news, events, success stories and new blogs releases.
Back to Blog
Northumbria House, Samson Close, Killingworth, Newcastle, NE12 6DX

